Introduction to Distributed Training
We use Distributed Data Parallel. This container provides data parallelism by synchronizing gradients across each model replica. The devices to synchronize across are specified by the input process_group, which is the entire world by default. Note that DistributedDataParallel does not chunk or otherwise shard the input across participating GPUs; the user is responsible for defining how to do so, for example through the use of a DistributedSampler
Tutorials
Check out the tutorials at: Getting Started with Distributed Data Parallel
Terminology
- A process or a worker (interchangeable terms) refers to an instance of the Python program. Each process controls a single, unique GPU. The number of available GPUs for distributed learning dictates the number of processes that are launched by DDP.
- A node or a host (another set of interchangeable terms) is a physical computer along with all of its hardware components (e.g., CPUs, GPUs, RAM, etc.). Each node is assigned a unique ID.
- World size is the total number of processes participating in training.
- The global rank is the unique ID assigned to each process. The process with global rank 0 is referred to as the main process.
- The local rank is the unique ID assigned to each process within a node.
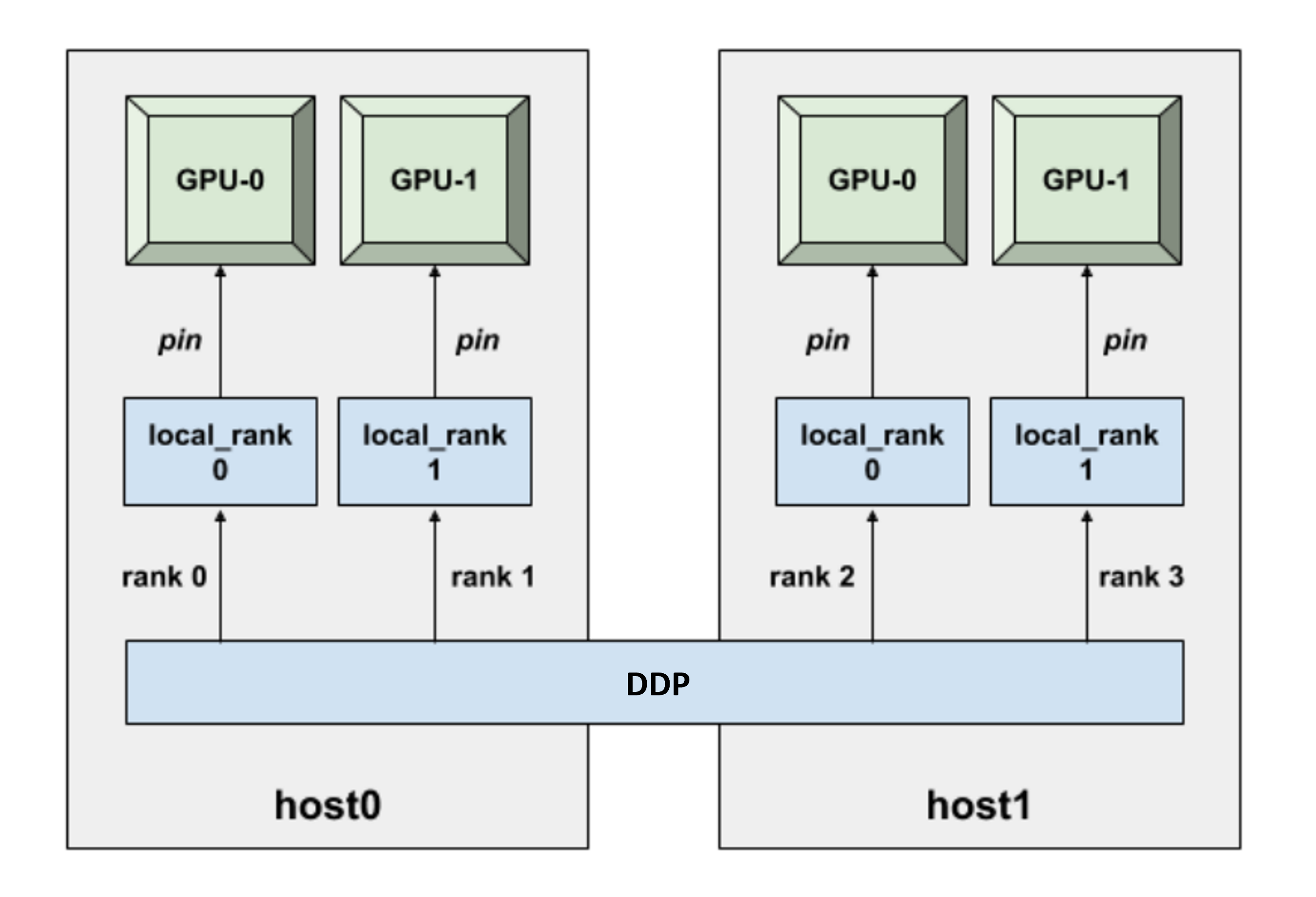
In data parallel training, the model architecture will be replicated across the available GPUs, with each GPU being fed a unique slice of the data. Training (i.e., forward propagation and backward propagation) is synchronously performed in a manner such that all model replicas are parametrized by the same weights. When it comes to setting up the model on each GPU (using torch.nn.parallel.DistributedDataParallel), an important point to note is that weights are initialized only on the main process (the rank 0 process), and are subsequently broadcasted to all other ranks. This is done to ensure all GPUs have the same copy of the model parameters before training commences. DDP addresses this synchronization internally. Following initialization, to send non-overlapping subsets of data to each GPU, we apply torch.utils.data.distributed.DistributedSampler. This allows each GPU to independently perform a forward pass operation, yielding a loss value. The calculated gradients are then broadcasted (via an all-reduce call), which provides an averaged gradient for each parameter in our model. A backward pass using the averaged gradients ensures that model parameters continue to be synchronized across all GPUs after a training step is complete. Communication and synchronization between processes is handled by the torch.distributed.init_process_group and the torch.nn.parallel.DistributedDataParallel methods.
Implementation
First one should include import torch.distributed as dist.
Then one should add arguments to the script:
parser.add_argument('--num-nodes', type=int, default=1,
help='Number of available nodes/hosts')
parser.add_argument('--node-id', type=int, default=0,
help='Unique ID to identify the current node/host')
parser.add_argument('--num-gpus', type=int, default=1,
help='Number of GPUs in each node') Then one should calculate world size and set IP address of the master:
WORLD_SIZE = args.num_gpus * args.num_nodes
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9956' Next step is to combine training script in worker(local_rank, args) and let the torch spawn the process:
if __name__ == '__main__':
torch.multiprocessing.spawn(worker, nprocs=args.num_gpus, args=(args,))Then distributed process group is initialized within worker with:
global_rank = args.node_id * args.num_gpus + local_rank
dist.init_process_group(
backend='nccl',
world_size=WORLD_SIZE,
rank=global_rank
) Next, download flag is used to prevent the dataset being downloaded more than once. Also include a call to dist.barrier() after the download step to ensure all other processes in a given node wait for the dataset to completely download.
download = True if local_rank == 0 else False
if local_rank == 0:
train_set = torchvision.datasets.FashionMNIST("./data", download=download, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=download, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
dist.barrier()
if local_rank != 0:
train_set = torchvision.datasets.FashionMNIST("./data", download=download, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=download, train=False, transform=
transforms.Compose([transforms.ToTensor()])) Each process/GPU will be receiving a unique slice of the data for forward propagation. This can be accomplished with torch.utils.data.distributed.DistributedSampler. For each epoch, this function splits the dataset into a number of segments determined by the world size. Each GPU is then assigned a unique segment to process with the prescribed batch size.
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
test_sampler = torch.utils.data.distributed.DistributedSampler(
test_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
# Training data loader
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=args.batch_size, drop_last=True, sampler=train_sampler)
# Validation data loader
test_loader = torch.utils.data.DataLoader(test_set,
batch_size=args.batch_size, drop_last=True, sampler=test_sampler)Then we set the GPU for the worker:
device = torch.device("cuda:" + str(local_rank) if torch.cuda.is_available() else "cpu")The default behavior of batchnorm layers in a distributed setting is to separately compute batch statistics for each process. Stated differently, for a given GPU, the mean and standard deviation for normalization are determined with only the slices of data passed to the device. Therefore, in any given training step, batch statistics do not capture all the batches processed in parallel by each GPU. This is not a significant issue when the batch size per device is large enough to obtain good statistics. However, as explored in the MegDet object detection paper, convergence and performance are negatively impacted if the batch size per device is very small. In such cases, it is important to synchronize batchnorm statistics across processes. To do this, we simply need to convert regular batchnorm layers to torch.nn.SyncBatchNorm by using torch.nn.SyncBatchNorm.convert_sync_batchnorm
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(
WideResNet(num_classes)
).to(device)
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])Also update sampling seed in each epoch:
train_sampler.set_epoch(epoch)At the end of every training epoch, synchronize (using dist.barrier())all processes to compute the slowest epoch time. To compute the number of images processed per second, convert images_per_sec into a tensor on the GPU, and then call torch.distributed.reduce on images_per_sec with global rank 0 as the destination process. The reduce operation computes the sum of images_per_sec across all GPUs and stores the sum in images_per_sec in the master process (global rank 0). Once this computation is done, enable the metrics print statement for only the master process.
dist.barrier()
epoch_time = time.time() - t0
total_time += epoch_time
images_per_sec = torch.tensor(len(train_loader)*args.batch_size/epoch_time).to(device)
torch.distributed.reduce(images_per_sec, 0)Since we are not validating the full dataset on each GPU anymore, each process will have different validation results. To improve validation metric quality and reduce variance, we will average validation results among all workers.
Final Solution
import argparse
import torch
import torch.nn as nn
import numpy as np
import os
import time
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
# TODO Step 0: Include DDP import statement for convenience
import torch.distributed as dist
# Parse input arguments
parser = argparse.ArgumentParser(description='Fashion MNIST Example',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--batch-size', type=int, default=32,
help='input batch size for training')
parser.add_argument('--epochs', type=int, default=40,
help='number of epochs to train')
parser.add_argument('--base-lr', type=float, default=0.01,
help='learning rate for a single GPU')
parser.add_argument('--target-accuracy', type=float, default=.85,
help='Target accuracy to stop training')
parser.add_argument('--patience', type=int, default=2,
help='Number of epochs that meet target before stopping')
# TODO Step 1: Add the following to the argument parser:
# number of nodes (num_nodes, type = int, default = 1),
# ID for the current node (node_id, type = int, default = 0)
# number of GPUs in each node (num_gpus, type = int, default = 1)
parser.add_argument('--num-nodes', type=int, default=1,
help='Number of available nodes/hosts')
parser.add_argument('--node-id', type=int, default=0,
help='Unique ID to identify the current node/host')
parser.add_argument('--num-gpus', type=int, default=1,
help='Number of GPUs in each node')
args = parser.parse_args()
# TODO Step 2: Compute world size (WORLD_SIZE) using num_gpus and num_nodes
# and specify the IP address/port number for the node associated with
# the main process (global rank = 0):
# os.environ['MASTER_ADDR'] = 'localhost'
# os.environ['MASTER_PORT'] = '9956'
WORLD_SIZE = args.num_gpus * args.num_nodes
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9956'
# Standard convolution block followed by batch normalization
class cbrblock(nn.Module):
def __init__(self, input_channels, output_channels):
super(cbrblock, self).__init__()
self.cbr = nn.Sequential(nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=(1,1),
padding='same', bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
def forward(self, x):
out = self.cbr(x)
return out
# Basic residual block
class conv_block(nn.Module):
def __init__(self, input_channels, output_channels, scale_input):
super(conv_block, self).__init__()
self.scale_input = scale_input
if self.scale_input:
self.scale = nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=(1,1),
padding='same')
self.layer1 = cbrblock(input_channels, output_channels)
self.dropout = nn.Dropout(p=0.01)
self.layer2 = cbrblock(output_channels, output_channels)
def forward(self, x):
residual = x
out = self.layer1(x)
out = self.dropout(out)
out = self.layer2(out)
if self.scale_input:
residual = self.scale(residual)
out = out + residual
return out
# Overall network
class WideResNet(nn.Module):
def __init__(self, num_classes):
super(WideResNet, self).__init__()
nChannels = [1, 16, 160, 320, 640]
self.input_block = cbrblock(nChannels[0], nChannels[1])
# Module with alternating components employing input scaling
self.block1 = conv_block(nChannels[1], nChannels[2], 1)
self.block2 = conv_block(nChannels[2], nChannels[2], 0)
self.pool1 = nn.MaxPool2d(2)
self.block3 = conv_block(nChannels[2], nChannels[3], 1)
self.block4 = conv_block(nChannels[3], nChannels[3], 0)
self.pool2 = nn.MaxPool2d(2)
self.block5 = conv_block(nChannels[3], nChannels[4], 1)
self.block6 = conv_block(nChannels[4], nChannels[4], 0)
# Global average pooling
self.pool = nn.AvgPool2d(7)
# Feature flattening followed by linear layer
self.flat = nn.Flatten()
self.fc = nn.Linear(nChannels[4], num_classes)
def forward(self, x):
out = self.input_block(x)
out = self.block1(out)
out = self.block2(out)
out = self.pool1(out)
out = self.block3(out)
out = self.block4(out)
out = self.pool2(out)
out = self.block5(out)
out = self.block6(out)
out = self.pool(out)
out = self.flat(out)
out = self.fc(out)
return out
def train(model, optimizer, train_loader, loss_fn, device):
model.train()
for images, labels in train_loader:
# Transfering images and labels to GPU if available
labels = labels.to(device)
images = images.to(device)
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Setting all parameter gradients to zero to avoid gradient accumulation
optimizer.zero_grad()
# Backward pass
loss.backward()
# Updating model parameters
optimizer.step()
def test(model, test_loader, loss_fn, device):
total_labels = 0
correct_labels = 0
loss_total = 0
model.eval()
with torch.no_grad():
for images, labels in test_loader:
# Transfering images and labels to GPU if available
labels = labels.to(device)
images = images.to(device)
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Extracting predicted label, and computing validation loss and validation accuracy
predictions = torch.max(outputs, 1)[1]
total_labels += len(labels)
correct_labels += (predictions == labels).sum()
loss_total += loss
v_accuracy = correct_labels / total_labels
v_loss = loss_total / len(test_loader)
return v_accuracy, v_loss
# TODO Step 3: Move all code (including comments) under __name__ == '__main__' to
# a new 'worker' function that accepts two inputs with no return value:
# (1) the local rank (local_rank) of the process
# (2) the parsed input arguments (args)
# The following is the signature for the worker function: worker(local_rank, args)
def worker(local_rank, args):
# TODO Step 4: Compute the global rank (global_rank) of the spawned process as:
# =node_id*num_gpus + local_rank.
# To properly initialize and synchornize each process,
# invoke dist.init_process_group with the approrpriate parameters:
# backend='nccl', world_size=WORLD_SIZE, rank=global_rank
global_rank = args.node_id * args.num_gpus + local_rank
dist.init_process_group(
backend='nccl',
world_size=WORLD_SIZE,
rank=global_rank
)
# TODO Step 5: initialize a download flag (download) that is true
# only if local_rank == 0. This download flag can be used as an
# input argument in torchvision.datasets.FashionMNIST.
# Download the training and validation sets for only local_rank == 0.
# Call dist.barrier() to have all processes in a given node wait
# till data download is complete. Following this, for all other
# processes, torchvision.datasets.FashionMNIST can be called with
# the download flag as false.
download = True if local_rank == 0 else False
if local_rank == 0:
train_set = torchvision.datasets.FashionMNIST("./data", download=download, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=download, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
dist.barrier()
if local_rank != 0:
train_set = torchvision.datasets.FashionMNIST("./data", download=download, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=download, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
# TODO Step 6: generate two samplers (one for the training
# dataset (train_sampler) and the other for the testing
# dataset (test_sampler) with torch.utils.data.distributed.DistributedSampler.
# Inputs to this function include:
# (1) the datasets (either train_loader_subset or test_loader_subset)
# (2) number of replicas (num_replicas), which is the world size (WORLD_SIZE)
# (3) the global rank (global_rank).
# Pass the appropriate sampler as a parameter (e.g., sampler = train_sampler)
# to the training and testing DataLoader
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
test_sampler = torch.utils.data.distributed.DistributedSampler(
test_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
# Training data loader
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=args.batch_size, drop_last=True, sampler=train_sampler)
# Validation data loader
test_loader = torch.utils.data.DataLoader(test_set,
batch_size=args.batch_size, drop_last=True, sampler=test_sampler)
# Create the model and move to GPU device if available
num_classes = 10
# TODO Step 7: Modify the torch.device call from "cuda:0" to "cuda:<local_rank>"
# to pin the process to its assigned GPU.
# After the model is moved to the assigned GPU, wrap the model with
# nn.parallel.DistributedDataParallel, which requires the local rank (local_rank)
# to be specificed as the 'device_ids' parameter: device_ids=[local_rank]
device = torch.device("cuda:" + str(local_rank) if torch.cuda.is_available() else "cpu")
# TODO Optional: before moving the model to the GPU, convert standard
# batchnorm layers to SyncBatchNorm layers using
# torch.nn.SyncBatchNorm.convert_sync_batchnorm.
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(WideResNet(num_classes)).to(device)
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
# Define loss function
loss_fn = nn.CrossEntropyLoss()
# Define the SGD optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=args.base_lr)
val_accuracy = []
total_time = 0
for epoch in range(args.epochs):
t0 = time.time()
# TODO Step 6.5: update the random seed of the DistributedSampler to change
# the shuffle ordering for each epoch. It is necessary to do this for
# the train_sampler, but irrelevant for the test_sampler. The random seed
# can be altered with the set_epoch method (which accepts the epoch number
# as an input) of the DistributedSampler.
train_sampler.set_epoch(epoch)
train(model, optimizer, train_loader, loss_fn, device)
# TODO Step 8: At the end of every training epoch, synchronize (using dist.barrier())
# all processes to compute the slowest epoch time.
# To compute the number of images processed per second, convert images_per_sec
# into a tensor on the GPU, and then call torch.distributed.reduce on images_per_sec
# with global rank 0 as the destination process. The reduce operation computes the
# sum of images_per_sec across all GPUs and stores the sum in images_per_sec in the
# master process (global rank 0).
# Once this computation is done, enable the metrics print statement for only the master process.
dist.barrier()
epoch_time = time.time() - t0
total_time += epoch_time
images_per_sec = torch.tensor(len(train_loader)*args.batch_size/epoch_time).to(device)
torch.distributed.reduce(images_per_sec, 0)
v_accuracy, v_loss = test(model, test_loader, loss_fn, device)
# TODO Step 9: average validation accuracy and loss across all GPUs
# using torch.distributed.all_reduce. To perform an average operation,
# provide 'dist.ReduceOp.AVG' as the input for the op parameter in
# torch.distributed.all_reduce.
torch.distributed.all_reduce(v_accuracy, op=dist.ReduceOp.AVG)
torch.distributed.all_reduce(v_loss, op=dist.ReduceOp.AVG)
val_accuracy.append(v_accuracy)
if global_rank == 0:
print("Epoch = {:2d}: Cumulative Time = {:5.3f}, Epoch Time = {:5.3f}, Images/sec = {}, Validation Loss = {:5.3f}, Validation Accuracy = {:5.3f}".format(epoch+1, total_time, epoch_time, images_per_sec, v_loss, val_accuracy[-1]))
if len(val_accuracy) >= args.patience and all(acc >= args.target_accuracy for acc in val_accuracy[-args.patience:]):
print('Early stopping after epoch {}'.format(epoch + 1))
break
# TODO Step 10: Within __name__ == '__main__', launch each process (total number of
# processes is equivalent to the number of available GPUs per node) with
# torch.multiprocessing.spawn(). Input parameters include the worker function,
# the number of GPUs per node (nprocs), and all the parsed arguments.
if __name__ == '__main__':
torch.multiprocessing.spawn(worker, nprocs=args.num_gpus, args=(args,))Algorithmic Challenges of Distributed SGD
We saw that throughput increased with batch size, but only to a certain point. As the batch size increased to saturate the GPU memory, we saw diminishing returns.
First Epoch
Since there are several overheads, first epoch performance in terms of frames/second doesn’t resemble actual performance. Wait until epoch 2.
We don’t get perfectly linear scaling with the increase in number of GPUs. A significant component of this is due to communication between the GPUs when updating weights. There can also be other factors, such as waiting for slower GPUs to finish processing before the weights are averaged. But still, this is pretty good.
So far, we’ve modified our training by altering batch size, as well as distributing across multiple GPUs. We’ll explore other hyperparameters, such as learning rate later in the lab. In this section, we’ll explore another key tool in improving our training process: selecting and tuning the optimizer that we use.
As you may recall in Lab 1, the optimizer updates the weights of the network in order to minimize the loss function. In the stochastic gradient descent optimizer that we’ve used so far, weights are updated based on their gradient with respect to the loss function of a mini-batch. In other words, we determine how altering a weight will affect the loss, and move a small step in the direction that minimizes that loss for the mini-batch. By taking those steps with each back-propagation, we slowly make our way toward a global minimum, decreasing our loss, and increasing our accuracy.
Though this process works well, it can be improved upon. One downside is that if the network gets near a local minimum or saddle point, the gradient can be quite small, and the training will slow down in that area. The noise introduced by using minibatches might help the model find its way out, but it might take some time.
Additionally, there may be areas where the algorithm keeps taking steps in roughly the same direction. It would be advantageous in those areas if the optimizer helped us take larger steps to move toward the global minimum faster.
A good solution to these issues is to use momentum. Instead of the algorithm taking a small independent step each time, adding momentum to our optimizer allows the process to retain a memory of the last several steps. If the weights have been moving in a certain direction on average, momentum will help continue to propel the updates in the same direction. If the training is also fluctuating back and forth, it can smooth out this movement. A decent analogy is a ball rolling down a hill, which will pick up and retain momentum.
optimizer = torch.optim.SGD(model.parameters(), lr=args.base_lr, momentum=args.momentum)Scaling Learning Rate with Batch Size
It’s important to recognize that when we scale our training to multiple GPUs, the batch size that we give each GPU is not the overall effective batch size. After each mini-batch is processed and a single GPU performs backpropagation, those weights are averaged among all the ranks. As a result, one update to the model takes into account every mini-batch, across all the GPUs. The effective batch size is therefore the size of the mini-batch multiplied by the number of GPUs. As a result, when more and more GPUs are used, the effective batch size can get very large.
As you saw in Lab 1, larger batch sizes can lead to drops in accuracy, especially in a network’s ability to generalize. The effect of a larger batch size also brings us closer to full batch gradient descent, and takes some of the variance or noise out of the process. Additionally, with a larger batch size fewer update steps are taken per epoch, which can slow down the training.
The common approach to adding variance back into the process, as well as accounting for fewer steps per epoch, is to increase the learning rate as you increase batch size. As the algorithm takes fewer steps per epoch, adjusting the learning rate compensates for this with a larger step each time.
Tip
Theory suggests that if we scale batch size by K, we should scale learning rate by the square root of K to maintain the variance. It’s also common in large scale training to adjust the learning rate linearly, by a factor of K.
Learning Rate Warm-up
It is often the case that a high learning rate at the beginning of a training can cause divergence. In this scenario, the weights are updated with a high enough magnitude that they overshoot, and never end up finding the slope toward a minimum.
In order to remedy this, we will implement a technique known as learning rate warm up. With this approach, the learning rate will start at a fraction of the target value, and slowly scale up over a series of epochs. This allows the network to move slowly at first, taking “careful steps” as it finds a slope toward the minimum. As the learning rate increases to the target value, the benefits of the larger learning rate will take effect.
scheduler = torch.optim.lr_scheduler.LinearLR(optimizer,
start_factor=1/args.num_gpus, total_iters=args.warmup_epochs)However, as scaling continues, and the batch size and learning rate increase, a problem can arise. When the learning rate is large, the update to the weights may be larger than the weights themselves, causing the training to diverge.
NovoGrad Optimizer Implementation
One of the solutions to the problem above is NovoGrad Optimizer.
optimizer = opt.NovoGrad(model.parameters(), lr=args.base_lr, grad_averaging=True)Final Code
import argparse
import torch
import torch.nn as nn
import numpy as np
import os
import time
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import torch.distributed as dist
import csv
## TODO NovoGrad: import the torch_optimizer library
import torch_optimizer as opt
# Parse input arguments
parser = argparse.ArgumentParser(description='Fashion MNIST Example',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--batch-size', type=int, default=32,
help='input batch size for training')
parser.add_argument('--epochs', type=int, default=40,
help='number of epochs to train')
parser.add_argument('--base-lr', type=float, default=0.01,
help='learning rate for a single GPU')
parser.add_argument('--target-accuracy', type=float, default=.85,
help='Target accuracy to stop training')
parser.add_argument('--patience', type=int, default=2,
help='Number of epochs that meet target before stopping')
parser.add_argument('--num-nodes', type=int, default=1,
help='Number of available nodes/hosts')
parser.add_argument('--node-id', type=int, default=0,
help='Unique ID to identify the current node/host')
parser.add_argument('--num-gpus', type=int, default=1,
help='Number of GPUs in each node')
## TODO momentum: add argument to accept the momentum parameter
parser.add_argument('--momentum', type=float, default=0.9,
help='SGD momentum')
## TODO warmup: add argument to accept the warmup epochs parameter
parser.add_argument('--warmup-epochs', type=float, default=5,
help='number of warmup epochs')
args = parser.parse_args()
WORLD_SIZE = args.num_gpus * args.num_nodes
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9956'
# Standard convolution block followed by batch normalization
class cbrblock(nn.Module):
def __init__(self, input_channels, output_channels):
super(cbrblock, self).__init__()
self.cbr = nn.Sequential(nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=(1,1),
padding='same', bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
def forward(self, x):
out = self.cbr(x)
return out
# Basic residual block
class conv_block(nn.Module):
def __init__(self, input_channels, output_channels, scale_input):
super(conv_block, self).__init__()
self.scale_input = scale_input
if self.scale_input:
self.scale = nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=(1,1),
padding='same')
self.layer1 = cbrblock(input_channels, output_channels)
self.dropout = nn.Dropout(p=0.01)
self.layer2 = cbrblock(output_channels, output_channels)
def forward(self, x):
residual = x
out = self.layer1(x)
out = self.dropout(out)
out = self.layer2(out)
if self.scale_input:
residual = self.scale(residual)
out = out + residual
return out
# Overall network
class WideResNet(nn.Module):
def __init__(self, num_classes):
super(WideResNet, self).__init__()
nChannels = [1, 16, 160, 320, 640]
self.input_block = cbrblock(nChannels[0], nChannels[1])
# Module with alternating components employing input scaling
self.block1 = conv_block(nChannels[1], nChannels[2], 1)
self.block2 = conv_block(nChannels[2], nChannels[2], 0)
self.pool1 = nn.MaxPool2d(2)
self.block3 = conv_block(nChannels[2], nChannels[3], 1)
self.block4 = conv_block(nChannels[3], nChannels[3], 0)
self.pool2 = nn.MaxPool2d(2)
self.block5 = conv_block(nChannels[3], nChannels[4], 1)
self.block6 = conv_block(nChannels[4], nChannels[4], 0)
# Global average pooling
self.pool = nn.AvgPool2d(7)
# Feature flattening followed by linear layer
self.flat = nn.Flatten()
self.fc = nn.Linear(nChannels[4], num_classes)
def forward(self, x):
out = self.input_block(x)
out = self.block1(out)
out = self.block2(out)
out = self.pool1(out)
out = self.block3(out)
out = self.block4(out)
out = self.pool2(out)
out = self.block5(out)
out = self.block6(out)
out = self.pool(out)
out = self.flat(out)
out = self.fc(out)
return out
def train(model, optimizer, train_loader, loss_fn, device):
model.train()
for images, labels in train_loader:
# Transfering images and labels to GPU if available
labels = labels.to(device)
images = images.to(device)
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Setting all parameter gradients to zero to avoid gradient accumulation
optimizer.zero_grad()
# Backward pass
loss.backward()
# Updating model parameters
optimizer.step()
def test(model, test_loader, loss_fn, device):
total_labels = 0
correct_labels = 0
loss_total = 0
model.eval()
with torch.no_grad():
for images, labels in test_loader:
# Transfering images and labels to GPU if available
labels = labels.to(device)
images = images.to(device)
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Extracting predicted label, and computing validation loss and validation accuracy
predictions = torch.max(outputs, 1)[1]
total_labels += len(labels)
correct_labels += (predictions == labels).sum()
loss_total += loss
v_accuracy = correct_labels / total_labels
v_loss = loss_total / len(test_loader)
return v_accuracy, v_loss
## TODO save data: copy the 'on_train_begin' function as well as the
## 'on_epoch_end' function from functions/save_training_data.py. The
## csv library has already been imported for you.
def on_train_begin(data_filepath):
file = open(data_filepath, 'w', newline='')
writer = csv.writer(file)
writer.writerow(['time', 'val_accuracy'])
writer.writerow([0.0, 0.0])
file.close()
def on_epoch_end(data_filepath, total_time, v_accuracy):
file = open(data_filepath, 'a')
writer = csv.writer(file)
writer.writerow([round(total_time,1), round(v_accuracy, 4)])
file.close()
def worker(local_rank, args):
global_rank = args.node_id * args.num_gpus + local_rank
dist.init_process_group(
backend='nccl',
world_size=WORLD_SIZE,
rank=global_rank
)
download = True if local_rank == 0 else False
if local_rank == 0:
train_set = torchvision.datasets.FashionMNIST("./data", download=download, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=download, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
dist.barrier()
if local_rank != 0:
train_set = torchvision.datasets.FashionMNIST("./data", download=download, transform=
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./data", download=download, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
test_sampler = torch.utils.data.distributed.DistributedSampler(
test_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
# Training data loader
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=args.batch_size, drop_last=True, sampler=train_sampler)
# Validation data loader
test_loader = torch.utils.data.DataLoader(test_set,
batch_size=args.batch_size, drop_last=True, sampler=test_sampler)
# Create the model and move to GPU device if available
num_classes = 10
device = torch.device("cuda:" + str(local_rank) if torch.cuda.is_available() else "cpu")
model = WideResNet(num_classes).to(device)
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
# Define loss function
loss_fn = nn.CrossEntropyLoss()
## TODO NovoGrad: replace the SGD optimizer with the NovoGrad optimizer
## TODO momentum: specify the momentum parameter in the SGD optimizer
# Define the SGD optimizer
optimizer = opt.NovoGrad(model.parameters(), lr=args.base_lr, grad_averaging=True)
## TODO warmup: define the scheduler using the torch.optim.lr_scheduler.LinearLR function
scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=1/args.num_gpus, total_iters=args.warmup_epochs)
val_accuracy = []
## TODO warmup: update the format of the csv file name.
## TODO momentum: update the format of the csv file name.
## TODO save data: define the file path for saving the csv file as
## data_filepath = "training_data/{}ranks-{}bs-{}lr.csv".format(WORLD_SIZE, args.batch_size, args.base_lr)
## Then, for only the main global rank 0 process, invoke the on_train_begin function
## to create and initialize the the csv file.
data_filepath = "training_data/{}ranks-{}bs-{}lr-{}m-{}w.csv".format(WORLD_SIZE, args.batch_size,
args.base_lr, args.momentum, args.warmup_epochs)
if global_rank == 0:
on_train_begin(data_filepath)
total_time = 0
for epoch in range(args.epochs):
t0 = time.time()
train_sampler.set_epoch(epoch)
train(model, optimizer, train_loader, loss_fn, device)
## TODO warmup: advance the scheduler to computer the next
## learning rate
scheduler.step()
dist.barrier()
epoch_time = time.time() - t0
total_time += epoch_time
images_per_sec = torch.tensor(len(train_loader)*args.batch_size/epoch_time).to(device)
torch.distributed.reduce(images_per_sec, 0)
v_accuracy, v_loss = test(model, test_loader, loss_fn, device)
torch.distributed.all_reduce(v_accuracy, op=dist.ReduceOp.AVG)
torch.distributed.all_reduce(v_loss, op=dist.ReduceOp.AVG)
val_accuracy.append(v_accuracy)
if global_rank == 0:
print("Epoch = {:2d}: Cumulative Time = {:5.3f}, Epoch Time = {:5.3f}, Images/sec = {}, Validation Loss = {:5.3f}, Validation Accuracy = {:5.3f}".format(epoch+1, total_time, epoch_time, images_per_sec, v_loss, val_accuracy[-1]))
## TODO save data: for only the global rank 0 process, update the
## csv file with total training time and the epoch validation accuracy
## using the on_epoch_end function. Note that you will have to
## convert the validation accuracy to a standard python number
## using torch.Tensor.item.
on_epoch_end(data_filepath, total_time, val_accuracy[-1].item())
if len(val_accuracy) >= args.patience and all(acc >= args.target_accuracy for acc in val_accuracy[-args.patience:]):
print('Early stopping after epoch {}'.format(epoch + 1))
break
if __name__ == '__main__':
torch.multiprocessing.spawn(worker, nprocs=args.num_gpus, args=(args,))Assignment
import argparse
import torch
import torch.nn as nn
import numpy as np
import os
import time
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import torch_optimizer as opt
# We use this special print function to help assess your work.
# Please do not remove or modify.
from assessment_print import assessment_print
import torch.distributed as dist
# Parse input arguments
parser = argparse.ArgumentParser(description='Workshop Assessment',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--batch-size', type=int, default=256,
help='input batch size for training')
parser.add_argument('--epochs', type=int, default=40,
help='number of epochs to train')
parser.add_argument('--base-lr', type=float, default=0.15,
help='learning rate for a single GPU')
parser.add_argument('--target-accuracy', type=float, default=.85,
help='Target accuracy to stop training')
parser.add_argument('--patience', type=int, default=2,
help='Number of epochs that meet target before stopping')
parser.add_argument('--num-nodes', type=int, default=1,
help='Number of available nodes/hosts')
parser.add_argument('--node-id', type=int, default=0,
help='Unique ID to identify the current node/host')
parser.add_argument('--num-gpus', type=int, default=1,
help='Number of GPUs in each node')
parser.add_argument('--momentum', type=float, default=0.9,
help='SGD momentum')
parser.add_argument('--warmup-epochs', type=float, default=5,
help='number of warmup epochs')
args = parser.parse_args()
WORLD_SIZE = args.num_gpus * args.num_nodes
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9956'
# Standard convolution block followed by batch normalization
class cbrblock(nn.Module):
def __init__(self, input_channels, output_channels):
super(cbrblock, self).__init__()
self.cbr = nn.Sequential(nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=(1,1),
padding='same', bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU()
)
def forward(self, x):
out = self.cbr(x)
return out
# Basic residual block
class conv_block(nn.Module):
def __init__(self, input_channels, output_channels, scale_input):
super(conv_block, self).__init__()
self.scale_input = scale_input
if self.scale_input:
self.scale = nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=(1,1),
padding='same')
self.layer1 = cbrblock(input_channels, output_channels)
self.dropout = nn.Dropout(p=0.01)
self.layer2 = cbrblock(output_channels, output_channels)
def forward(self, x):
residual = x
out = self.layer1(x)
out = self.dropout(out)
out = self.layer2(out)
if self.scale_input:
residual = self.scale(residual)
out = out + residual
return out
# Overall network
class WideResNet(nn.Module):
def __init__(self, num_classes):
super(WideResNet, self).__init__()
nChannels = [3, 16, 160, 320, 640]
self.input_block = cbrblock(nChannels[0], nChannels[1])
# Module with alternating components employing input scaling
self.block1 = conv_block(nChannels[1], nChannels[2], 1)
self.block2 = conv_block(nChannels[2], nChannels[2], 0)
self.pool1 = nn.MaxPool2d(2)
self.block3 = conv_block(nChannels[2], nChannels[3], 1)
self.block4 = conv_block(nChannels[3], nChannels[3], 0)
self.pool2 = nn.MaxPool2d(2)
self.block5 = conv_block(nChannels[3], nChannels[4], 1)
self.block6 = conv_block(nChannels[4], nChannels[4], 0)
# Global average pooling
self.pool = nn.AvgPool2d(7)
# Feature flattening followed by linear layer
self.flat = nn.Flatten()
self.fc = nn.Linear(nChannels[4], num_classes)
def forward(self, x):
out = self.input_block(x)
out = self.block1(out)
out = self.block2(out)
out = self.pool1(out)
out = self.block3(out)
out = self.block4(out)
out = self.pool2(out)
out = self.block5(out)
out = self.block6(out)
out = self.pool(out)
out = self.flat(out)
out = self.fc(out)
return out
def train(model, optimizer, train_loader, loss_fn, device):
total_labels = 0
correct_labels = 0
model.train()
for images, labels in train_loader:
# Transfering images and labels to GPU if available
labels = labels.to(device)
images = images.to(device)
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Setting all parameter gradients to zero to avoid gradient accumulation
optimizer.zero_grad()
# Backward pass
loss.backward()
# Updating model parameters
optimizer.step()
predictions = torch.max(outputs, 1)[1]
total_labels += len(labels)
correct_labels += (predictions == labels).sum()
t_accuracy = correct_labels / total_labels
return t_accuracy
def test(model, test_loader, loss_fn, device):
total_labels = 0
correct_labels = 0
loss_total = 0
model.eval()
with torch.no_grad():
for images, labels in test_loader:
# Transfering images and labels to GPU if available
labels = labels.to(device)
images = images.to(device)
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Extracting predicted label, and computing validation loss and validation accuracy
predictions = torch.max(outputs, 1)[1]
total_labels += len(labels)
correct_labels += (predictions == labels).sum()
loss_total += loss
v_accuracy = correct_labels / total_labels
v_loss = loss_total / len(test_loader)
return v_accuracy, v_loss
def worker(local_rank, args):
global_rank = args.node_id * args.num_gpus + local_rank
dist.init_process_group(
backend='nccl',
world_size=WORLD_SIZE,
rank=global_rank
)
# Load and augment the data with a set of transformations
transform_train = transforms.Compose([transforms.RandomHorizontalFlip(), # Flips the image w.r.t horizontal axis
transforms.RandomRotation(10), # Rotates the image to a specified angle
transforms.RandomAffine(0, shear=10, scale=(0.8,1.2)), # Performs actions like zooms, change shear angles.
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # Set the color params
transforms.ToTensor(), # Convert the image to tensor so that it can work with torch
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # Normalize all the images
])
transform_test = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
download = True if local_rank == 0 else False
if local_rank == 0:
train_set = torchvision.datasets.CIFAR10("./data", download=download, transform=
transform_train)
test_set = torchvision.datasets.CIFAR10("./data", download=download, train=False, transform=
transform_test)
dist.barrier()
if local_rank != 0:
train_set = torchvision.datasets.CIFAR10("./data", download=download, transform=
transform_train)
test_set = torchvision.datasets.CIFAR10("./data", download=download, train=False, transform=
transform_test)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
test_sampler = torch.utils.data.distributed.DistributedSampler(
test_set,
num_replicas=WORLD_SIZE,
rank=global_rank
)
# Training data loader
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=args.batch_size, drop_last=True, sampler=train_sampler)
# Validation data loader
test_loader = torch.utils.data.DataLoader(test_set,
batch_size=args.batch_size, drop_last=True, sampler=test_sampler)
# Create the model and move to GPU device if available
num_classes = 10
device = torch.device("cuda:" + str(local_rank) if torch.cuda.is_available() else "cpu")
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(WideResNet(num_classes)).to(device)
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
# Define loss function
loss_fn = nn.CrossEntropyLoss()
# Define the SGD optimizer
optimizer = opt.NovoGrad(model.parameters(), lr=args.base_lr, grad_averaging=True)
scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=1/args.num_gpus, total_iters=args.warmup_epochs)
val_accuracy = []
total_time = 0
for epoch in range(args.epochs):
train_sampler.set_epoch(epoch)
t0 = time.time()
t_accuracy = train(model, optimizer, train_loader, loss_fn, device)
scheduler.step()
dist.barrier()
epoch_time = time.time() - t0
total_time += epoch_time
images_per_sec = torch.tensor(len(train_loader)*args.batch_size/epoch_time).to(device)
torch.distributed.reduce(images_per_sec, 0)
v_accuracy, v_loss = test(model, test_loader, loss_fn, device)
torch.distributed.all_reduce(v_accuracy, op=dist.ReduceOp.AVG)
torch.distributed.all_reduce(v_loss, op=dist.ReduceOp.AVG)
val_accuracy.append(v_accuracy)
# We use this special print function to help assess your work.
# Please do not remove or modify.
if global_rank == 0:
assessment_print("Epoch = {:2d}: Cumulative Time = {:5.3f}, Epoch Time = {:5.3f}, Images/sec = {}, Training Accuracy = {:5.3f}, Validation Loss = {:5.3f}, Validation Accuracy = {:5.3f}".format(epoch+1, total_time, epoch_time, images_per_sec, t_accuracy, v_loss, val_accuracy[-1]))
if len(val_accuracy) >= args.patience and all(acc >= args.target_accuracy for acc in val_accuracy[-args.patience:]):
# We use this special print function to help assess your work.
# Please do not remove or modify.
assessment_print('Early stopping after epoch {}'.format(epoch + 1))
break
if __name__ == '__main__':
torch.multiprocessing.spawn(worker, nprocs=args.num_gpus, args=(args,))