Notes from papers
A Survey on Deep Active Learning: Recent Advances and New Frontiers
Info
Check the paper.
Summary
The survey is from 2024, and list most recent deep active learning directions. The survey further goes into the limitation of the current research which is summarized below:
1Uncertainty based methods: have some common drawbacks: (1) redundant samples, as uncertain points, are continually selected yet in short of coverage; (2) simply focusing on a single sample lacks robustness to outliers; (3) these task-specific designs exhibit limited generalization.
2Representative-based methods: which are methods that aim to sample the most prototypical data points that effectively cover the distribution of the entire feature space. Such methods have two subcategories: (1) Density based methods that select samples that can represent all unlabeled sample and (2) Diversity-based methods that select samples that are different from the labeled samples. Main weakness with Diversity-based method is that it solely focus on sampling diverse samples, are always insensitive to samples that are close to the decision boundary. Moreover, such the representative methods have computational complexity is almost quadratic with respect to data size.
3Influence-based methods: which aim to select samples that will have the greatest impact on the performance of the target model. The main weakness is that directly measuring model changes or incorporating new learning policies always requires huge time and space costs, and training a new model will over-rely on its accuracy and often lead to unstable results.
4Bayesian methods: main weakness is that the often require extensive accurate prior knowledge and tend to under perform deep learning models in representation learning and fitting capacity.
Challenges and research directions:
1Inefficient & Costly Human Annotation: what if human annotators did not exit. some suggestions include: 1use pseudo labels for samples with high confidence 2use multiple annotators in an partial unsupervised framework . Yet these directions might be unstable and need more research.
2Insufficient Research on Stopping Strategies: model does not know when to stop, when more examples will no further improve the model accuracy on a certain dataset.
3Cold start: Most uncertainty method assume an initial model which is very well trained and has good accuracy, with small amount of labels to start with the model might not be mature enough
4Unstable Performance: Active learning methods always have unstable performance, i.e., results for the same method vary significantly with different initialized seeds. The initial selected samples have a great influence on the eventual outcome of the current approaches. With insufficient initial labeling, subsequent DAL cycles become highly biased, resulting in poor selection. Separating the deep learning from sampling is a problem too. One solution is to perform sampling in the latent space
5Outlier Data & Noisy Oracles: DAL methods tend to acquire outliers since models always assign high uncertainty scores to outliers. Outliers can damage a model’s learning ability and fuel a vicious cycle in which DAL methods continue to select them.
6Data Scarcity & Imbalance : Data scarcity poses two critical challenges. First, datasets are difficult to collect and annotate [ Second, DAL methods have the common underlying assumption that all classes are equal, while some classes have more samples than others (skewed class distribution )
7Class Distribution Mismatch: DAL methods assume that the labeled and unlabeled data are drawn from the same class distribution, which means that the categories of both datasets are identical. However, in real-world scenarios, unlabeled data often come from uncontrolled sources, and a large portion of the examples may belong to unknown classes.
DAL models are first trained on an initial training dataset. Then, query strategies can be iteratively applied to select the most informative and representative samples from a large pool of unlabeled data. Finally, an oracle labels the selected samples and adds them to the training dataset for retraining or fine-tuning of the DAL models. DAL aims to achieve competitive performance while reducing annotation costs within a reasonable time [2]– [4]. A Survey on Deep Active Learning Recent Advances and New Frontiers, page 1
As a methodology for selecting or generating a subset of training data in data-centric AI, DAL is closely related to learning settings and practical techniques, including curriculum learning [10], transfer learning [11], data augmentation or pruning [12], [13], and dataset distillation [14]. The commonality of these methods is to train or fine-tune a model using a small number of samples, aiming to remove noise and redundancy while improving training efficiency without decreasing models’ performance on downstream tasks. However, one primary difference from DAL is that these approaches have full access to all labels when selecting, distilling, or generating training subsets. DAL defaults to that all data should be unlabeled during the training subset selection process, making it better suited for real-world scenarios where labels are initially unavailable. A Survey on Deep Active Learning Recent Advances and New Frontiers, page 1

Dual Domain Control via Active Learning for Remote Sensing Domain Incremental Object Detection
See the
Domain incremental object detection in remote sensing addresses the challenge of adapting to continuously emerging domains with distinct characteristics.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 1
Incremental object detection methods can be categorized into knowledge distillation-based methods [8, 9, 22, 28, 47], example replay-based methods [8, 9, 16, 26, 27], and adapter-based methods [10, 37, 38, 41, 43]. Knowledge distillation and example replay methods are particularly effective as they do not require additional network parameters, making them popular in incremental learning. While some methods perform well in multi-domain incremental object detection tasks on natural images, remote sensing images present unique challenges, particularly in data and feature distribution.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 2
Problem in remote-sensing
Remote sensing deal with various sensor setups, altitudes and terrain. These factors challenge the extraction and alignment of features across the domains.
Contributions of this paper
The main contributions of this work are summarized as follows:
- To the best of our knowledge, we are the first to formulate the task of domain-incremental object detection for remote sensing images and propose the Active-DDC method.
- We introduce the Data-based Active Learning Example Replay (ALER) module, which effectively mitigates data migration in incremental tasks and enhances the representativeness of selected examples.
- We propose the Query-based Active Domain Shift Control (ADSC) module, which addresses feature shifts in incremental tasks and enables effective cross-domain knowledge transfer through query-based preselection and optimal transport matching.
- Extensive experiments demonstrate that our approach achieves state-of-the-art performance, with ablation studies further validating the effectiveness of our proposed modules.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 2
Domain incremental object detection aims to train a model to detect objects across a sequence of tasks, where each task consists of a set of images xt from the t-th domain. The model should be able to detect objects in new domain images while preserving its ability to detect objects in previously encountered domains , without experiencing catastrophic forgetting. However, domain increment introduces two primary effects: the shift in data distribution and the shift in feature vectors.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 3
This paper uses Incremental object detection and Continuous learning.
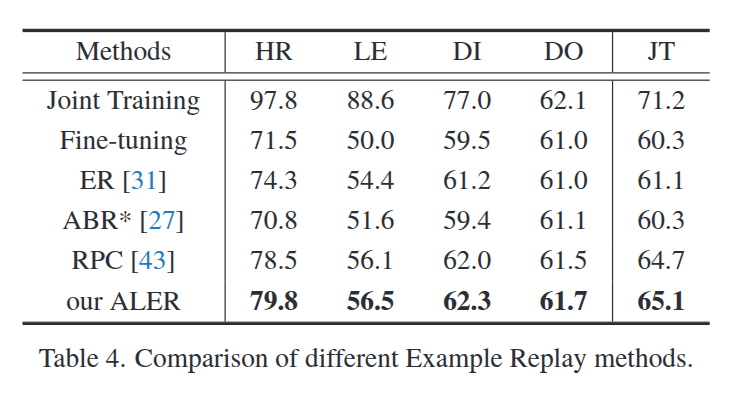
Data-based Active Learning Example Replay (ALER)
Summary
Data-based Active Learning Example Replay (ALER) module, combines a high information sample selection strategy from active learning with the characteristic extreme foreground-background ratio in remote sensing images, enabling the selection of highly representative samples for storage in a memory bank.
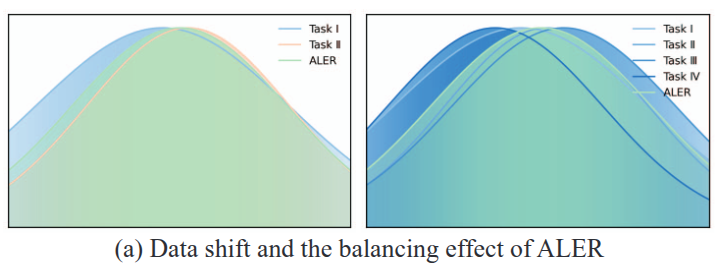 Illustrates the data distribution for two-task and four-task settings, along with the combined training data distribution generated by ALER, demonstrating its effectiveness in balancing data distribution shifts.
Illustrates the data distribution for two-task and four-task settings, along with the combined training data distribution generated by ALER, demonstrating its effectiveness in balancing data distribution shifts.
Data-based Active Learning Example Replay (ALER), mitigates data distribution shifts, as illustrated in fig. 1(a). It employs an active learning strategy to select representative samples, which are stored in a memory bank. By preserving essential information from previous domains, ALER effectively minimizes the impact of data distribution shifts as new domains emerge.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 2
ALER module leverages an active learning-based high-information sample selection strategy, ensuring that the most representative samples are stored in the memory bank for effective knowledge retention. To address model feature shifts, the ADSC module exploits query vectors in DETR-based detectors, implementing query preselection and an optimal transport-based matching mechanism to achieve effective many-to-many query alignment, thereby enhancing crossdomain knowledge transfer.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 3
Selection Process
After each task: Compute for all candidate samples in the buffer. Rank samples by score. Keep high-scoring samples in the memory bank. During new task training: Train jointly on new domain data + memory bank samples. Memory bank is dynamic: Low-score samples are discarded. New informative samples are added
 Overview of our Active-DDC framework. During cross-domain adaptation, ALER first selects highly representative samples and stores them in a memory bank. Then, the model is jointly trained using both the memory bank and the new domain data. Finally, ADSC controls query vector shifts to mitigate domain drift. Active-DDC effectively suppresses both data and feature shifts caused by domain changes.
Overview of our Active-DDC framework. During cross-domain adaptation, ALER first selects highly representative samples and stores them in a memory bank. Then, the model is jointly trained using both the memory bank and the new domain data. Finally, ADSC controls query vector shifts to mitigate domain drift. Active-DDC effectively suppresses both data and feature shifts caused by domain changes.
As far as I understand, this paper uses Continuous learning in Example relay section. It keeps most informative data from each domain and keep it in the memory bank. Then uses this bank to get samples from it in the other domain’s training.
At the start of task t, ALER pre-selects difficult samples based on the false positive rate (FPR) and false negative rate (FNR), which are stored in the memory buffer Bt−1 for further processing after task t − 1 training.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 4
After applying the scoring ranking mechanism, the memory bank M t−1 holds highly representative samples. The ranking mechanism considers information complexity, sample difficulty, and foreground-background uncertainty, following active learning principles to score and retain high-scoring samples for joint training with Dt during task t.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 4
Based on entropy and foreground-background ratio scores, ALER dynamically selects and discards samples from both new and old tasks. This selective approach helps the model better adapt to new domains while retaining knowledge from previous domains, reducing the impact of data distribution shifts.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 4
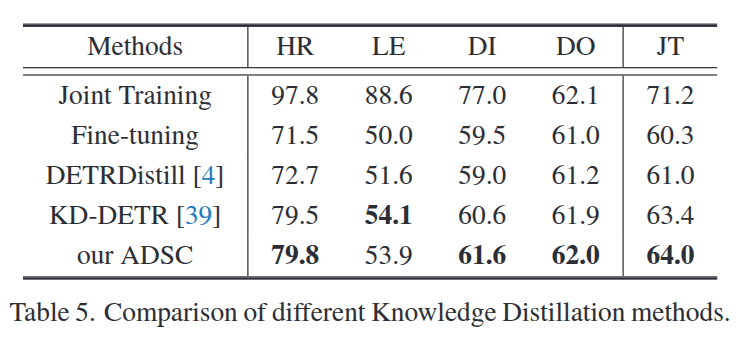
Query-based Active Domain Shift Control (ADSC)
Summary
Query-based Active Domain Shift Control (ADSC) module, leverages the query vector, a key element for DETR-based detectors, to implement query active preselection and optimal transport matching, thus facilitating effective cross-domain knowledge transfer.
 Presents the T-SNE visualization of query features from the Fine-tuning model and the ADSC-trained model on incremental data, highlighting ADSC’s capability in mitigating feature shift.
Presents the T-SNE visualization of query features from the Fine-tuning model and the ADSC-trained model on incremental data, highlighting ADSC’s capability in mitigating feature shift.
Query-based Active Domain Shift Control (ADSC), addresses the feature shift problem inherent in domain-incremental learning, with its control effect on feature migration depicted in fig. 1(b). By leveraging a query selection strategy combined with optimal transport matching, ADSC facilitates knowledge distillation from the previous domain. The class distillation mechanism helps preserve essential features, ensuring that the model effectively retains critical knowledge while adapting to new domains.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 2
Active Domain Shift Control (ADSC), which integrates knowledge distillation with active learning. ADSC first preselects highly overlapping queries for distillation, then applies optimal transport for multi-to-multi query matching, enhancing knowledge transfer. This allows the student model to retain essential knowledge while extracting richer semantic information.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 4
DETR, the query vectors are unordered and dynamic. They do not have any inherent order or explicit category label association, and during training, the query vectors are dynamically adjusted based on the features of the input image. Additionally, the focus of each query may shift as the task progresses. To address this, query Active Preselection is applied to preselect and match query vectors. After the training of task t − 1 is completed, we use both the teacher model F t−1 θ and student model F t θ to perform detection and calculate the Intersection over Union (IoU) between their predicted boxes. Based on the IoU values, we filter out query vectors with significant overlap for subsequent knowledge distillation. This step effectively removes queries with low semantic relevance, thereby reducing ineffective learning.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 5
This optimal transport method ensures that the student model learns richer knowledge from the teacher model by aligning query vectors between the target and source, thereby enhancing performance in incremental tasks.
Dual Domain Control via Active Learning for Remote Sensing Domain, page 5
So this part is about Knowledge distillation.
From Easy to Hard: Progressive Active Learning Framework for Infrared Small Target Detection with Single Point Supervision
Inspired by organisms gradually adapting to their environment and continuously accumulating knowledge, we construct an innovative Progressive Active Learning (PAL) framework for single point supervision, which drives the existing SIRST detection networks progressively and actively recognizes and learns more hard samples to achieve significant performance improvements
Meanwhile, we propose a refined dual-update strategy, which can promote reasonable learning of harder samples and continuous refinement of pseudo-labels. In addition, to alleviate the risk of excessive label evolution, a decay factor is reasonably introduced, which helps to achieve a dynamic balance between the expansion and contraction of target annotations
However, existing SIRST detection methods focus on full supervision, which requires expensive pixel-level dense annotations. To reduce the annotation cost, Ying et al. recently propose a LESPS framework [61] that combines the existing excellent SIRST detection network with continuous pseudo-label evolution to achieve SIRST detection with single point supervision. However, from the Sec. A of Supplementary Materials and Fig. 1, the LESPS framework has problems such as instability, excessive label evolution, and difficulty in exerting embedded network performance.
Our PAL can be classified as automatic Curriculum learning [53]. However, unlike previous automatic CL that focuses on full supervision or other weakly supervised tasks [25, 26, 48, 54, 78], this paper is the first attempt to explore its derivation to single point supervision tasks and construct an effective learning framework for infrared small target detection with single point supervision
Contributions
The contributions can be summarized as follows:
- We construct an innovative PAL framework that can transfer existing SIRST detection networks to single point supervision tasks and drive them to progressively and actively learn more hard samples, thereby achieving continuous performance improvements.
- A model pre-start concept is proposed, which focuses on automatically selecting a portion of easy samples and can help models have basic task-specific learning capabilities. For this task, we construct an EPG strategy to achieve the initial selection of easy samples and the generation of corresponding pseudo-labels.
- A fine dual-update strategy is proposed, which can promote reasonable learning of harder samples and continuous refinement of pseudo-labels.
- To alleviate the risk of excessive label evolution, a decay factor is reasonably introduced, which helps achieve a dynamic balance between the expansion and contraction of target annotations.
Agnostic Active Learning Is Always Better Than Passive Learning
Info
Active Learning from Scene Embeddings for End-to-End Autonomous Driving
See the paper.
we propose an active learning framework that relies on these vectorized scene-level features, called SEAD. The framework selects initial data based on driving-environmental information and incremental data based on BEV features. Experiments show that we only need 30% of the nuScenes training data to achieve performance close to what can be achieved with the full dataset. Active Learning from Scene Embeddings for End-to-End Autonomous Driving, page 1
In complex and dynamic driving environments, E2E approaches demonstrate the potential to handle diverse scenarios and better tackle real-world challenges. However, E2E-AD models have higher data requirements [Caesar et al., 2020; Jia et al., 2024]. … To alleviate these labeling costs, active learning has emerged as a promising solution. By selecting the most informative samples for labeling, active learning aims to achieve high model performance with fewer labeled examples, thus reducing both labeling and training expenses [Ren et al., 2021; Zhan et al., 2022]. Active Learning from Scene Embeddings for End-to-End Autonomous Driving, page 1
There is an urgent need to find a data selection strategy that does not depend on manually set selection rules and is more generalizable to different data distributions. BEV algorithms [Philion and Fidler, 2020; Huang et al., 2021; Liu et al., 2023] shine in AD by virtue of their ability to comprehensively perceive the environment, efficiently fuse multi-sensor data, and improve system stability and reliability. BEV-Former [Li et al., 2022] achieved state-of-the-art performance in perception tasks using solely visual inputs. Active Learning from Scene Embeddings for End-to-End Autonomous Driving, page 1
We first leverage the abundant dynamic and static information in AD datasets to construct a diverse initial dataset, which is used to train a baseline model. Using this baseline model, we extract BEV features from the remaining data to evaluate scene value based on the predefined rule. The rule can be summarized as extracting key elements from BEV features and calculating the cumulative changes in these elements at the clip level as the selection criterion. For valuable scenes, key consecutive frames are selected and labeled, then combined with the existing data for further rounds of training and refinement. Active Learning from Scene Embeddings for End-to-End Autonomous Driving, page 2